Detecção de Máscara de Proteção Facial usando Mask R-CNN
Introdução
Um dos conceitos mais importantes e que ganha cada vez mais destaque na área de Deep Learning e Inteligência Artificial é o conceito de visão computacional. Visão computacional estuda como reconstruir, interromper e, em sua base, compreender as propriedades e estruturas de uma imagem. Uma parte integrante de visão computacional é o reconhecimento de imagens, desde o reconhecimento de objetos até análise de sentimentos. Uma das arquiteturas mais conhecidas e utilizadas para reconhecimento de imagens é o Mask R-CNN que será a arquitetura que vamos estudar e aplicar ao longo deste artigo. Desde já, adianto que um notebook com código completo desse artigo pode ser consultado no seguinte repositório do Github.
Problemática
As máscaras de proteção facial junto do isolamento social são as duas formas de proteção que mais ganharam destaque durante essa crise do covid-19. Por este motivo, para este artigo, o dataset ou conjunto de dados que vamos utilizar vai ser o de imagens de máscaras disponibilizado no Kaggle. Esse dataset tem cerca de 853 imagens de pessoas utilizando máscaras e que podem ser divididos em três classes: com máscara, sem máscara e máscara vestida incorretamente. Nosso objetivo vai ser utilizar o Mask R-CNN para detectar e reconhecer cada uma dessas classes em imagens.
Uma característica interessante desse dataset, assim como da maioria que trabalha com reconhecimento de imagens, é que ele fornece os dados seguindo um padrão bastante único. Esses dados são divididos em dados de imagens e um arquivo extra, geralmente Json ou XML, que fornece os rótulos ou labels dos objetos que serão reconhecidos nas imagens. Além disso, também fornece as posições onde podemos encontrar o objeto a ser reconhecido em um formato de caixa que veremos mais adiante.
Mask R-CNN
O que é o Mask R-CNN
O Mask R-CNN é uma arquitetura que permite a segmentação de imagens. A segmentação, basicamente, além de classificar e reconhecer objetos em imagens, permite o reconhecimento dos pixels que compõem a forma dos objetos a serem reconhecidos, como se fosse uma máscara por cima da imagem. Essa abordagem de segmentação da imagem é bastante utilizada em problemas como a detecção de doenças, uma vez que permite saber o tamanho ou expansão dessa doença. Um outro exemplo é o caso dos carros autônomos, já que é necessário saber a posição de cada carro.
Como é a arquitetura do Mask R-CNN
O Mask R-CNN é um modelo desenvolvido com base no Faster R-CNN. O Faster R-CNN é uma arquitetura que utiliza as redes neurais convolucionais para detecção de regiões, retornando uma caixa contendo o objeto reconhecido e sua classe com uma probabilidade ao qual ele acredita que aquele objeto pertence a aquela classe. Essa arquitetura consiste, de forma simplificada, de duas etapas. Na primeira, uma série de camadas convolucionais, geralmente um modelo VGG16, ResNet, Inception ou outro do tipo é utilizado para gerar como saída um mapa de features. Esses features, por sua vez, são passados por uma rede especial chamada de Rede de Proposta de Regiões (RPN).
Essa rede é composta, basicamente, por uma ou mais camadas convolucionais com um regressor e um classificador. O classificador não é nosso classificador final, mas sim um classificador para determinar a probabilidade de um dos pixels do mapa de features ser um terreno (background) ou um objeto, enquanto que o regressor determina as coordenadas para essa caixa contendo o objeto que foi detectado.
Já o segundo passo é utilizar uma camada de Pooling na saída da RPN para garantir que todas as imagens passadas adiante vão ter o mesmo tamanho. Em sequência, essas imagens são passadas por uma arquitetura tradicional de camadas densamente conectadas e se bifurca em mais duas sub-redes. Em uma delas estará o nosso classificador final com uma ativação, geralmente Softmax, responsável por reconhecer os objetos. Na outra estará um regressor responsável por estimar a melhor caixa para o objeto/objetos reconhecidos. Toda essa arquitetura do Faster R-CNN pode ser resumida na figura abaixo.

A diferença do Mask R-CNN para o Faster R-CNN é que na segunda etapa, logo após a camada de Pooling existe uma nova bifurcação que gera, no total, duas sub-redes. Em uma delas estão as camadas densamente conectadas faladas anteriormente, enquanto na outra estarão algumas camadas convolucionais que serão responsáveis por fazer a segmentação dos pixels. A imagem abaixo resume a arquitetura do Mask R-CNN.
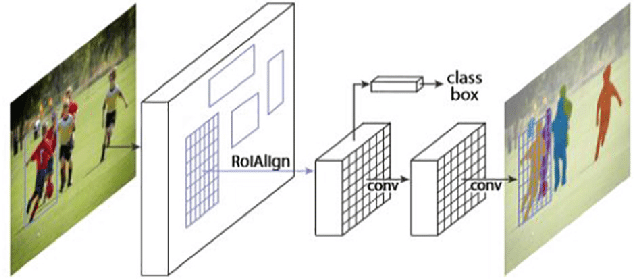
Implementação do Mask R-CNN
Diferente das outras arquiteturas de Deep Learning que podem ser facilmente encontrado em grandes bibliotecas como o TensorFlow, Keras ou Pytorch, é difícil encontrar uma boa implementação do Mask R-CNN. Entretanto, é possível encontrar uma implementação bastante famosa da Matterport. Apesar disso, faz um longo período de tempo que essa biblioteca não é atualizada, o que faz com que surjam diversos bugs, principalmente de falta de compatibilidade. Uma versão corrigida pode ser encontrada no meu repositório do github.
Essa biblioteca exige que criemos algumas classes de configuração antes de começar a treinar o modelo. Uma delas é uma classe geral de configuração, nela vamos poder alterar diversos parâmetros do modelo. A outra classe é uma classe que será responsável por lidar com o nosso dataset e, nessa classe, somos obrigados a implementar 2 métodos que vão facilitar bastante a nossa vida. O primeiro deles (load_dataset) carrega as imagens do nosso dataset, gera a configuração inicial das classes e separa a nossa base de dados em dados de treinamento e dados de teste. O segundo (load_mask) é o método que o modelo utilizará para encontrar as caixas (bounding boxes) e as classes de cada objeto a ser reconhecido na imagem.
class CustomConfig(Config):
NAME = "mask_detection"
IMAGES_PER_GPU = 1
GPU_COUNT = 1
IMAGE_MIN_DIM = 448
BATCH_SIZE = 1
IMAGE_MAX_DIM = 704
NUM_CLASSES = 1 + 3 #background + as três classes
STEPS_PER_EPOCH = 100
DETECTION_MIN_CONFIDENCE = 0.7
RPN_ANCHOR_SCALES = (32, 64, 128, 256)
BACKBONE = 'resnet50'class MaskDataset(utils.Dataset):
def load_dataset(self, dataset_dir, is_train=True):
self.add_class("mask_detection", 1, "without_mask")
self.add_class("mask_detection", 2, "with_mask")
self.add_class("mask_detection", 3, "mask_weared_incorrect")images_dir = dataset_dir + '/images/'
annotations_dir = dataset_dir + '/annotations/maksssksksss'
total_of_images = len(list(listdir(images_dir)))
test_index = total_of_images - total_of_images*0.1 #separa 10% da base de dados como treinamentofor filename in listdir(images_dir):
image_id = int("".join(list(filter(str.isdigit, filename))))# pula todas as imagens depois do indice de teste caso seja treino
if is_train and image_id > test_index:
continue
# pula todas as imagens antes do indice de teste caso seja teste
if not is_train and int(image_id) < test_index:
continue
image_path = images_dir + filename
ann_path = annotations_dir + str(image_id) + '.xml'self.add_image('mask_detection', image_id=image_id, path=image_path , annotation=ann_path, class_ids=[0,1,2,3])def find_bounding_boxes(self, path_annotations):
tree = ElementTree.parse(path_annotations)
root = tree.getroot()
boxes = []
for box in root.findall('.//object'):
name = box.find('name').text
xmin = int(box.find('./bndbox/xmin').text)
ymin = int(box.find('./bndbox/ymin').text)
xmax = int(box.find('./bndbox/xmax').text)
ymax = int(box.find('./bndbox/ymax').text)
boxes.append([xmin, ymin, xmax, ymax, name])width = int(root.find('.//size/width').text)
height = int(root.find('.//size/height').text)
return boxes, width, heightdef load_mask(self, image_id):
path = self.image_info[image_id]['annotation']
boxes, w, h = self.find_bounding_boxes(path)
masks = np.zeros([h, w, len(boxes)], dtype='uint8')class_ids = []
for i in range(len(boxes)):
box = boxes[i]
row_s, row_e = box[1], box[3]
col_s, col_e = box[0], box[2]
#refatorar depois
if (box[4] == "without_mask"):
masks[row_s:row_e, col_s:col_e, i] = 1
class_ids.append(self.class_names.index("without_mask"))
elif (box[4] == "with_mask"):
masks[row_s:row_e, col_s:col_e, i] = 2
class_ids.append(self.class_names.index("with_mask"))
else:
masks[row_s:row_e, col_s:col_e, i] = 3
class_ids.append(self.class_names.index("mask_weared_incorrect"))return masks, np.asarray(class_ids, dtype='int32')
Apenas com base nessas configurações podemos carregar os nossos datasets em conjuntos de treino e teste e estamos prontos para criar o modelo. Nessa parte, a biblioteca utilizada permite uma opção interessante que é utilizar a técnica de transfer learning para pré-carregar os pesos iniciais do nosso modelo. Utilizando essa técnica podemos utilizar os pesos de modelos maiores e bem treinados e adaptar esses pesos para o nosso dataset. Essa opção economiza tempo e processamento computacional, uma vez que um dos grandes problemas da área de visão computacional é o tempo gasto para treinar os modelos.
config = CustomConfig()
COCO_WEIGHTS_PATH = "/content/Mask_RCNN/mask_rcnn_coco.h5"train_dataset = MaskDataset()
train_dataset.load_dataset("/content/", is_train=True)
train_dataset.prepare()test_dataset = MaskDataset()
test_dataset.load_dataset("/content/", is_train=False)
test_dataset.prepare()train_model = modellib.MaskRCNN(mode='training', config=config, model_dir= "/content/Mask_RCNN/logs")
train_model.load_weights(COCO_WEIGHTS_PATH, by_name=True, exclude=[
"mrcnn_class_logits", "mrcnn_bbox_fc",
"mrcnn_bbox", "mrcnn_mask"])
Nesse trabalho foram utilizados os pesos de um modelo de reconhecimento de objetos treinado no dataset COCO que é um dataset em larga escala para reconhecimento de imagens. Claro que outros pesos poderiam ter sido utilizados, mas o COCO é um dos mais utilizados e recomendados. Com apenas essas poucas configurações o modelo está treinado e pronto para o reconhecimento de imagens, gerando como resultado uma imagem como essa abaixo.

Note que o modelo previu com uma grande acurácia onde estaria o rosto do homem, assim como previu com uma alta probabilidade que essa é uma imagem de alguém sem máscara de proteção, o que está correto. Uma outra característica que pode ser percebida é a segmentação da imagem como uma máscara de pixels vermelha que cobre o rosto da pessoa.

Já a imagem acima mostra um caso onde diversas pessoas estão utilizando máscara de proteção e o modelo consegue prever com precisão onde é o rosto de cada pessoa, assim como o fato delas estarem de máscara. Entretanto, uma outra característica que pode ser percebida é que o modelo erra ao prever que o ombro de uma das mulheres se trata de uma pessoa de máscara. Esse erro pode ter ocorrido, por exemplo, devido a todas as máscaras de proteção cirúrgicas serem da cor branca, o que fez com que o modelo confundisse a roupa da mulher.
Conclusão
Neste artigo focamos em explicar, de forma simplificada, os conceitos por trás de uma das arquiteturas mais utilizadas para reconhecimento de imagens, o Mask R-CNN. Existe uma dificuldade em encontrar bibliotecas grandes ou oficiais que implementem essa arquitetura e as open source que podem ser encontradas exibem alguns problemas de incompatibilidade. Entretanto, essa arquitetura exibe ótimos resultados quando se trata em trabalhar com imagens. Com poucas configurações e até pré-carregando alguns pesos utilizando a técnica de transfer learning conseguimos criar um modelo eficiente e que funcionou na nosso problema de prever ou não o uso de máscaras de proteção facial. O código completo com todos os detalhes do processo de criação do modelo pode ser visualizado no meu repositório do Github. Até uma próxima!